- Maxime
- 23 mars, 2018
Dans cet article, nous voulons partager avec vous une des nouvelles fonctionnalités qui vont arriver dans ARender dans la version 3.1.10.
ARender va dorénavant être livré avec un mécanisme d’autoscaling de ses worker. Pendant longtemps, nous avons expliqué comment ARender fonctionne de manière interne en ayant un nombre fixe de tâches pouvant être traitées en parallèle.
Bien qu’efficace à traiter les documents, ce système a montré dans des scénarios particuliers des faiblesses notables. En exemple, nous allons aujourd’hui prendre le cas d’une ouverture d’un trop grand nombre de conversion de documents de longue durée.
Améliorations existantes (depuis ARender 3.1.8)
Pour améliorer la performance des conversions de document Office, nous avons utilisé des paramètres de conversion libreoffice afin de permettre de ne plus convertir les documents de manière séquentielle mais dorénavant de manière parallèle. Ceci a permis à notre backend de traitement libreoffice d’être aussi parallélisable que notre backend de conversion Microsoft Office.
Malgré ces améliorations, un problème reste non résolu : que se passe-t-il quand un document contenant un nombre de documents supérieur au maximum parallélisable est ouvert ? Nous allons étudier en détails le cas d’une archive de 318 documents office.
Le début de la tempête
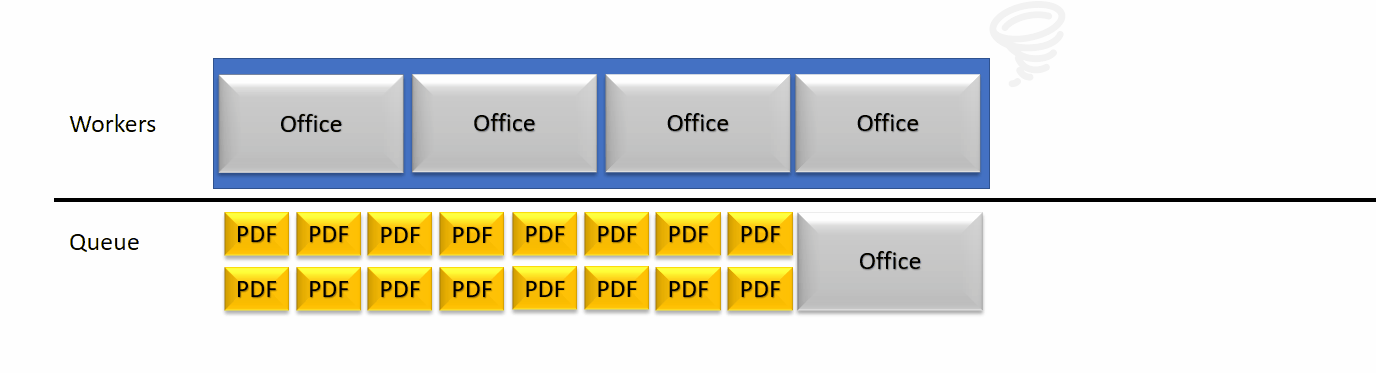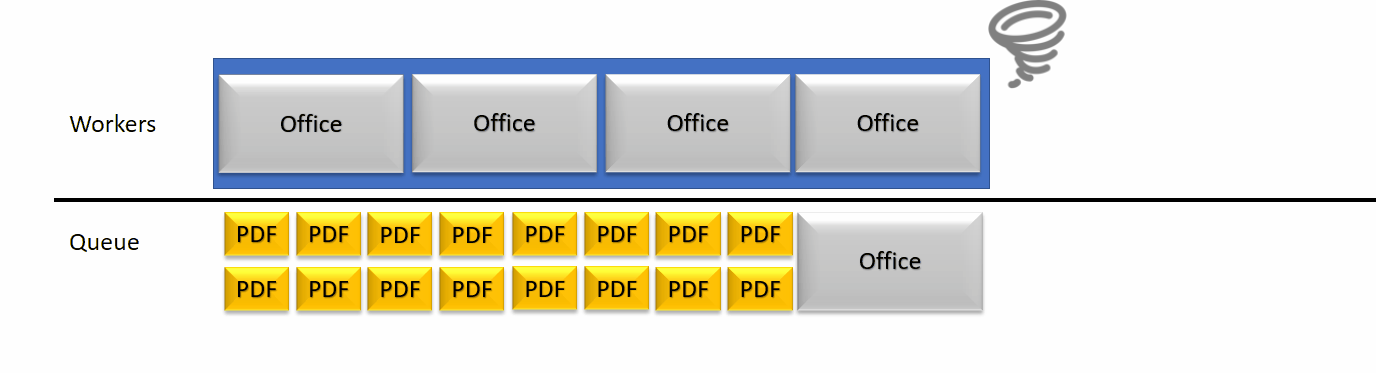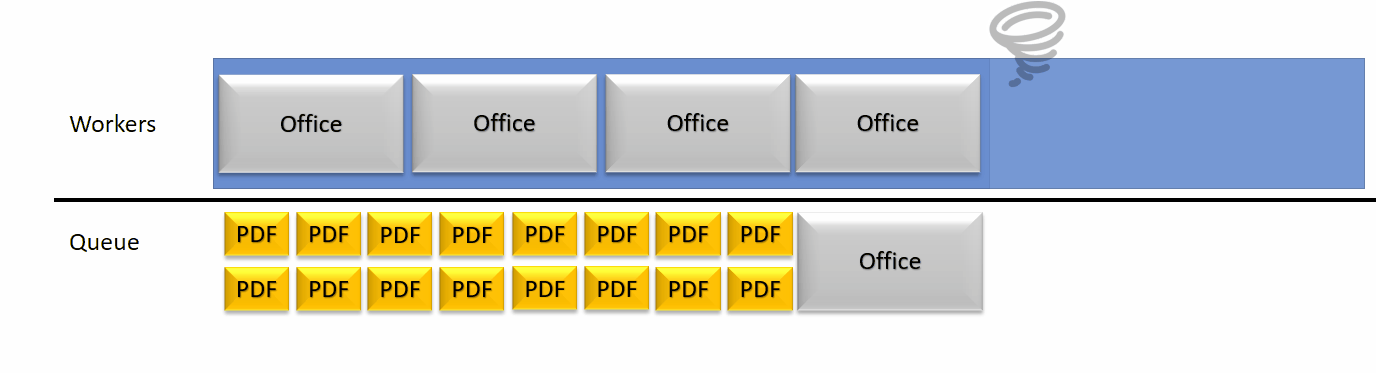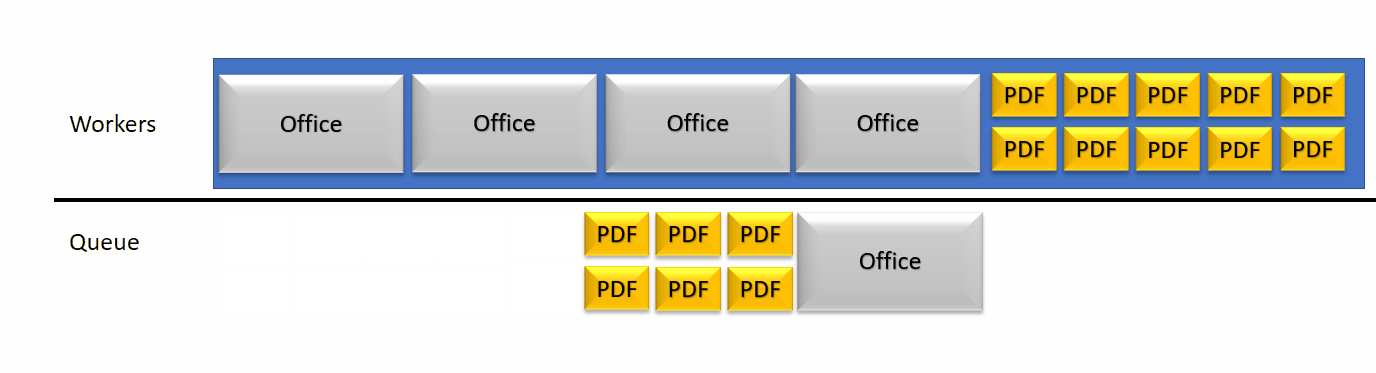
Une archive de 318 documents insérée dans une file de traitement linéaire est très basique : à moins d’avoir 318 unité de travail au minimum, il va y avoir du temps d’attente perdu.
Pendant ce temps, le serveur de rendition peut toujours recevoir des appels/requêtes et les empiler. Cette pile va alors grossir jusqu’à ce que les temps d’expiration sont tous atteints. Cela cause des problèmes d’accumulation de threads en attente de réponse (dans une quantité raisonnable pour un serveur de rendition) mais parfois compliqués à gérer pour un serveur d’application web. Si le serveur Web atteint une limite de thread, nous arrivons à de l’indisponibilité de service.
Pour diminuer les risques
Comme la branche 3.1.x arrive en fin de vie, refaire l’architecture du backend de rendition était une option hors périmètre car pouvant trop facilement impacter la stabilité du produit.
Afin de consolider la performance et améliorer la stabilité, nous avons réfléchi à de nouvelles façons de pouvoir réduire le temps d’attente dans les files, tout en utilisant les traitements parallèles au besoin. La principale tâche du serveur de rendition est de transformer des documents PDF en images, et ce rôle est fait avec brio et rapidité. Ces tâches PDF sont rapides, et peuvent facilement se glisser entre deux conversions de documents s’il y avait la place.
Nous avons donc décidé de détecter activement l’état de nos threads travailleurs afin de voir si la situation arrive à un état de blocage. Si le serveur se détecte comme bloqué par une trop forte occupation de ses threads travailleurs, il va alors se marquer comme en panne par l’API ARender afin de limiter ses connexions entrantes.
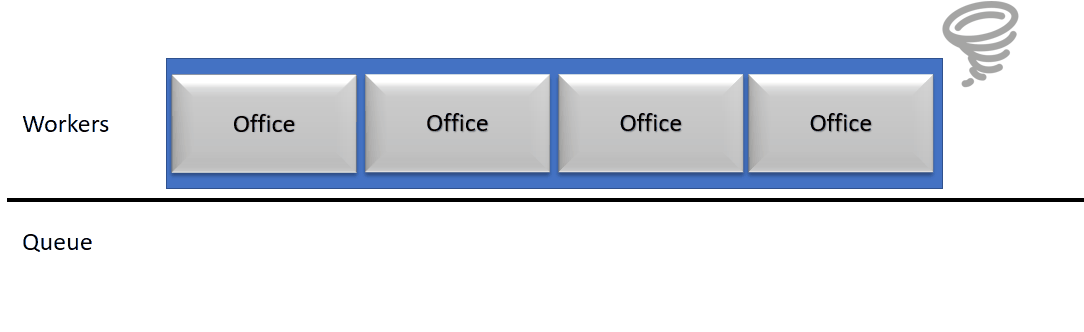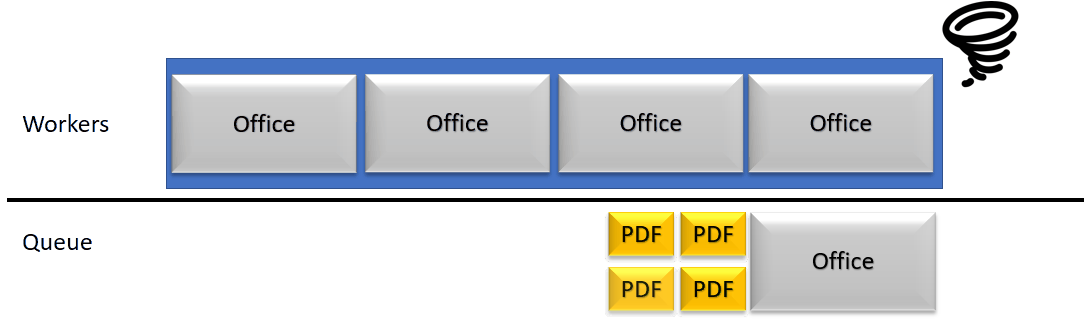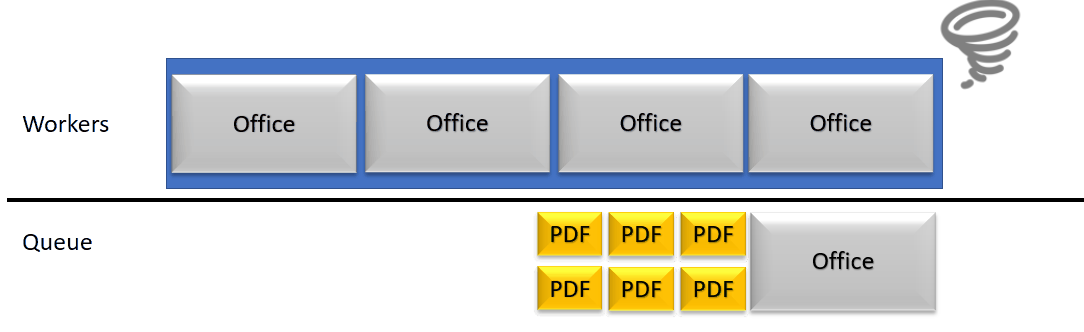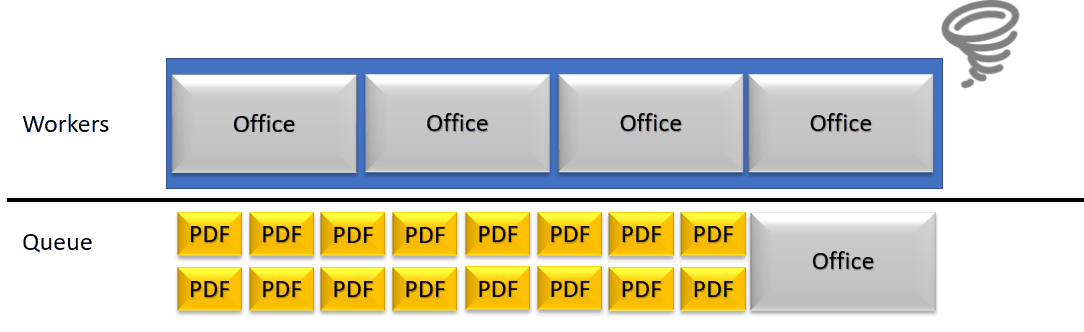
Cette détection d’une panne peut ensuite donner en fonction de la configuration à une augmentation automatique du nombre de threads de travail de la rendition. Cela libère de la place pour les petites unités de travail et ensuite le nombre de threads pourra à nouveau diminuer.
Dans les chiffres
Utiliser un grand nombre de thread en parallèle va augmenter les possibilités de traitement concurrent mais peut dans certains cas diminuer le temps unitaire de part certains effets de bord liés à l’utilisation maximale de la machine.
Par exemple, pendant nos tests, nous avons observé pendant le parsing des 318 documents Office que:
- le nombre de thread de travail a doublé
- le temps total était 6% plus rapide
- chaque document a été 50% plus lent à convertir
La seconde grosse différence entre les deux cas est que sans l’autoscaling des threads, d’autres documents n’auraient pas pu être traités par le serveur alors que l’autoscaling autorise d’en ajouter au détriment d’une dégradation de performance unitaire. Le taux maximal de CPU et mémoire utilisé sur le serveur peuvent être configuré: si les taux sont atteints, les threads n’augmentent plus.
Le véritable use case
Nous avons finalement lancé deux Jmeter concurrent sur une stack ARender complète (front + rendition server) : le premier Jmeter contenant des documents office le second des documents PDF. Chaque Jmeter simule une charge de trois documents par seconde.
En utilisant libreoffice (ou potentiellement MSOffice), il y aura un moment où la stack ne pourra plus traiter les documents PDF aussi rapidement de par la saturation du Jmeter Office.
En utilisant l’autoscaling des threads, le serveur de rendition (sizé pour être capable de traiter les trois documents par seconde) adapte son nombre de threads pour répondre à la charge et se stabilise. L’utilisation globale du CPU du serveur est également meilleure.