- Maxime
- 23 Mar, 2018
- Tech articles
In this article, we would like to share with you a sneak peek of what is to come natively in one of the last releases the branch 3.1.x of ARender will see.
Starting with 3.1.10, ARender will ship with an autoscaling feature. For a long time we explained how ARender internally works with a set amount of Workers that can be tuned precisely in order to improve the local server performance.
While proving itself very convenient, it could lead to subpar performance on some edge cases. As an example we are going to study today we will see the specific case of Office documents conversions, when sent in large quantities.
Base improvement (since 3.1.8)
To improve the base performance of Office document conversion, we used configuration parameters to pilot Libreoffice (one of our backends) to do parallel document conversions in order to speed up the total processing time. This put Libreoffice conversion speed on par in terms of parallelism with MicrosoftOffice backend documents conversion.
A problem though remains : what if someone uploads an archive document containing 318 Word files?
Where the storm begins
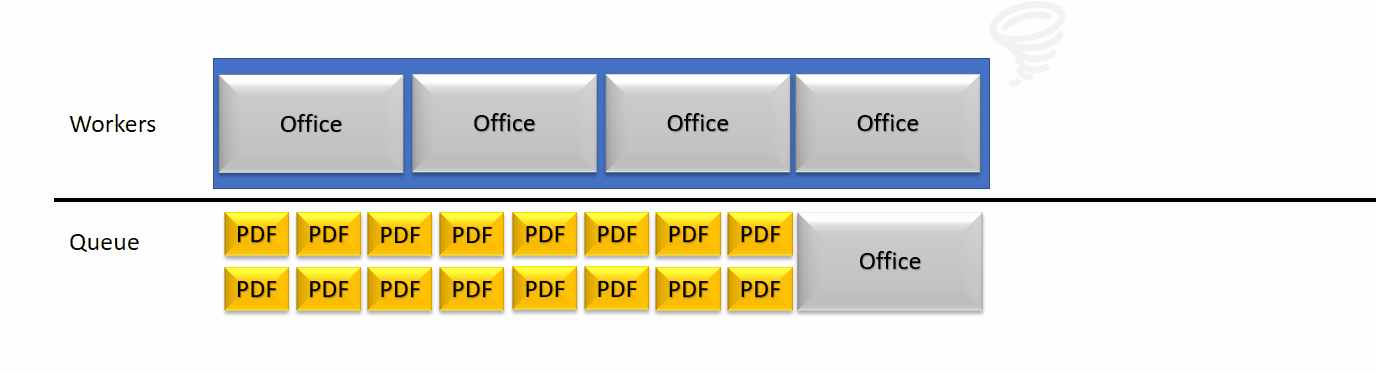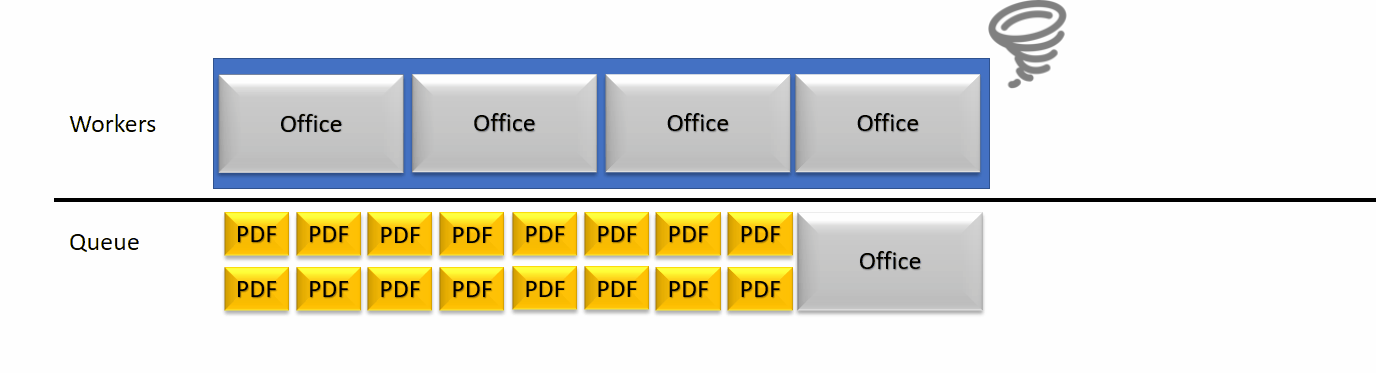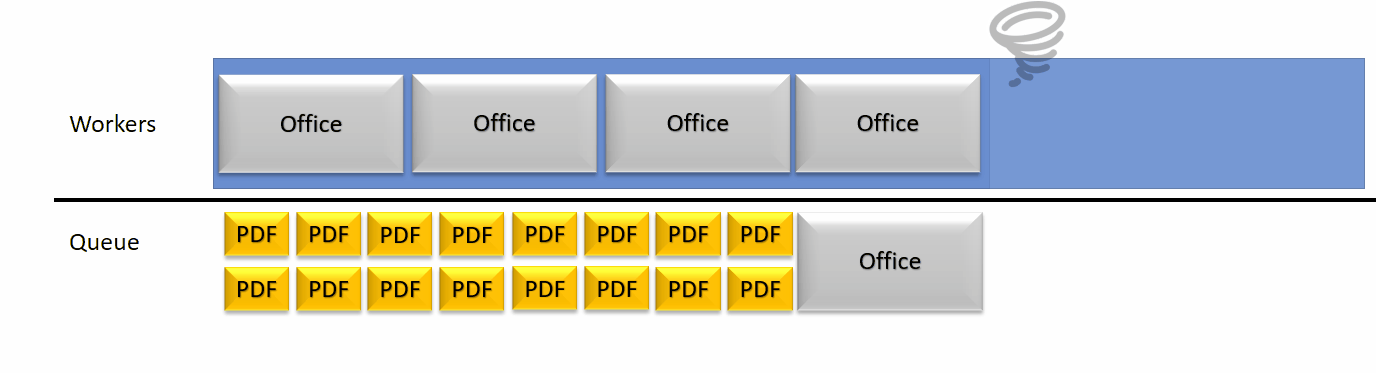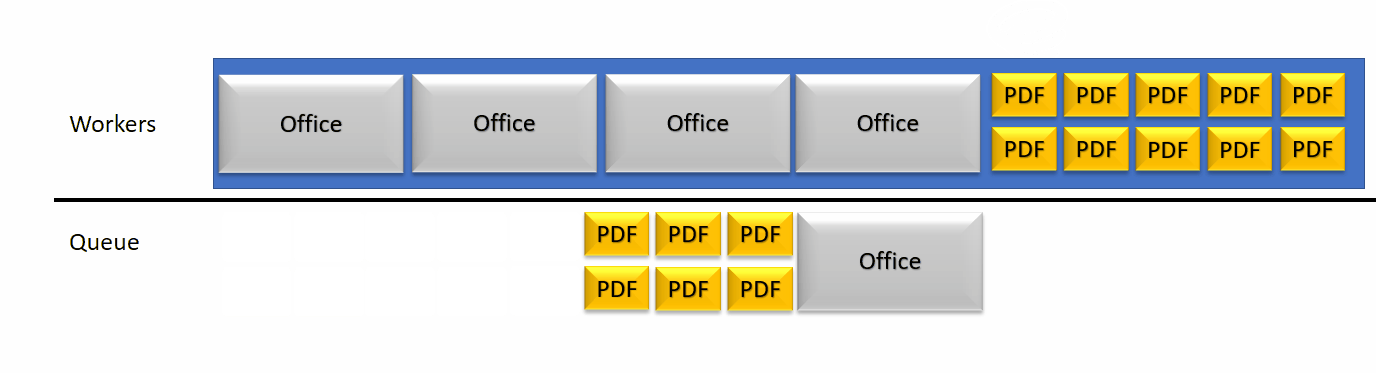
An archive of 318 documents in a fixed set of Workers doing jobs in a queue is very straightforward : unless you have 318 workers, you are going to work on this Archive for quite some time.
Meanwhile, the rendition server treating the archive can still receive new requests and queue them up. They will eventually stack up until the time out is reached (2mn for long documents conversions). This causes not only the backend side to acumulate threads (in a reasonable safe quantity) but as well the front end servers. If the front end servers reach maximum threads capacity, it’s a service outage.
To lower the risks
As the branch 3.1.x is getting close to an end of support in regards of new Evolutions to the product, redesigning the entire mechanism of the rendition servers was not an option.
In order to consolidate the performance and increase its stability, we thought about ways to lower the waiting queue of threads, while still using parallel treatments where needed. Most of the workload of the rendition servers rely on PDF documents, which for us are fast and efficient to parse. Those smaller tasks can get blocked behind, huge, slow jobs. We therefor detect in our worker pool which one is blocked and relatively to a threshold, consider the server as crashed.
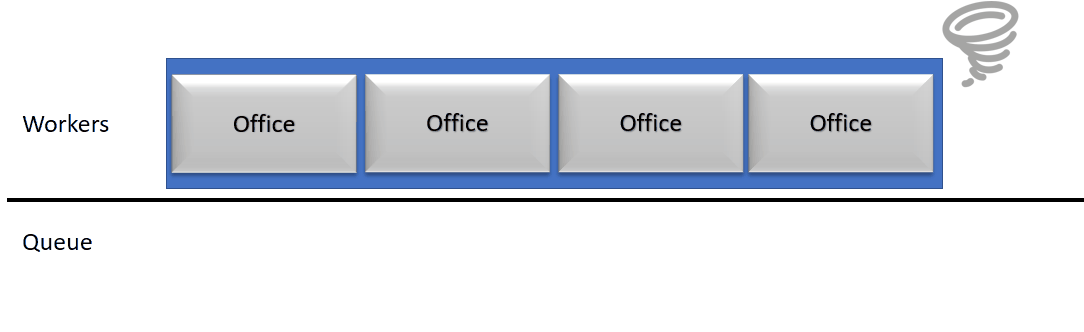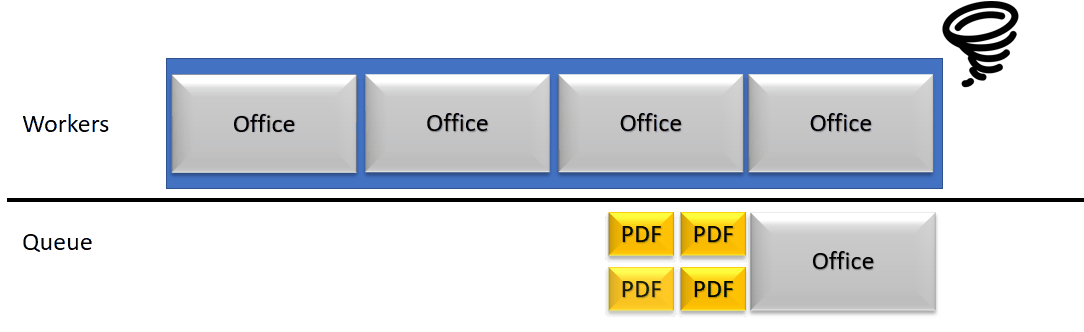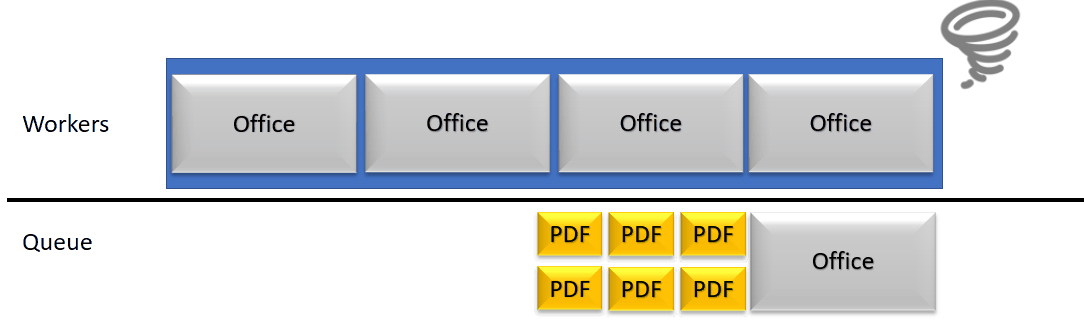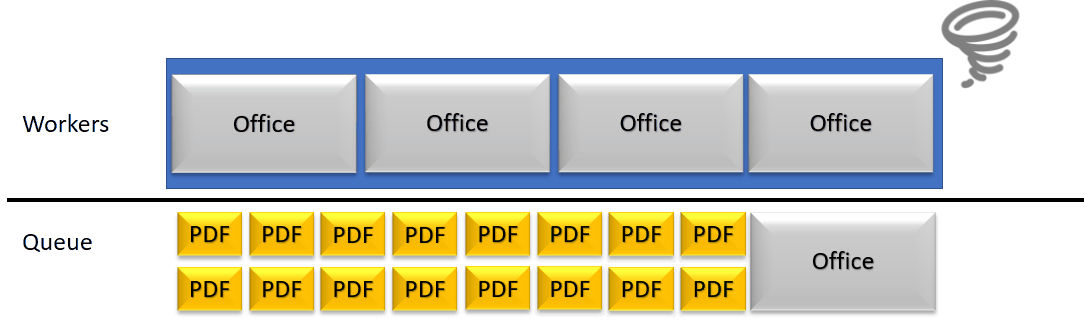
This detection of a crash then lead to a configurable increase of the thread pool size to free some queued jobs.
In numbers
Using a higher number of concurrent parsing of documents allows for much more parallel processing but as well is going to consume more CPU than available on the local machine in some edge cases.
In short, using this approach the server will recover from a high amount of slow parallel document requests, but can loose peak power on single document conversions.
As an example, during our tests, we found that for the 318 Word documents file the worker pool size doubled, was 6% faster at converting all documents but got 50% slower per document conversion than the controlled conversion at a maximum of 6 fixed workers (from 4 seconds to 6 seconds).
The real use case
We finally ran two Jmeter concurrently on the full stack of ARender (front + rendition server) : one containg Word documents and one containing PDF documents. Each Jmeter simulates a 3 documents/second load.
Using any Libreoffice conversion parameter without an autoscaling the PDF Jmeter will eventually not progress after a some time once enough Office documents have went through.
Using an autoscaling rendition server, both Jmeter behave like they are expected to and proceed (even though slower than they should) at a constant pace.